Enhancing Animal Welfare through Sound Recognition
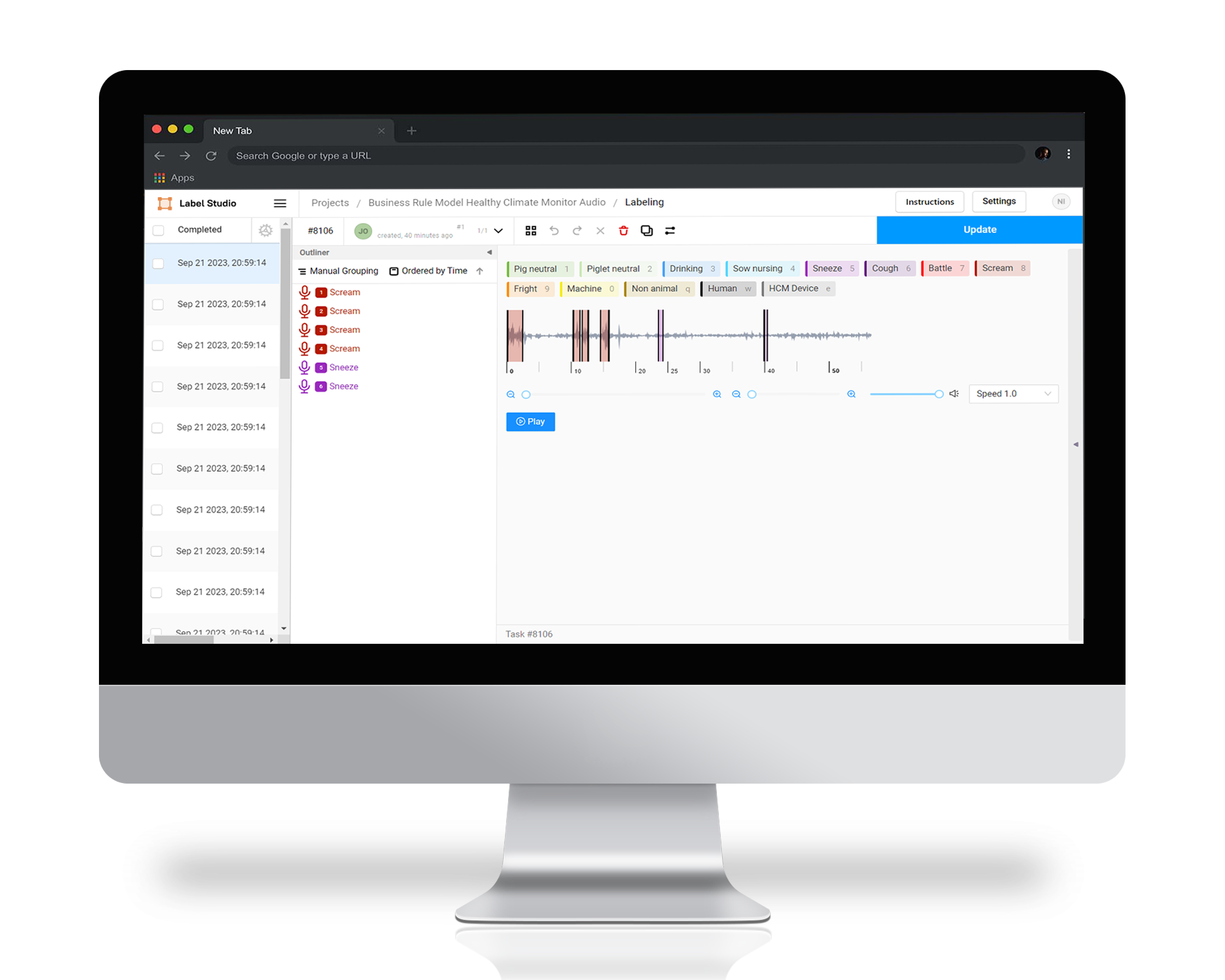
This initiative aimed to enhance the functionality of the Healthy Climate Monitor, a hardware device designed for integration into animal stables. The primary purpose of this device is to provide crucial insights into the stable environment, ultimately enhancing the quality of life for the animals housed there. Our objective was to augment the intelligence of the Healthy Climate Monitor by utilizing its microphone to autonomously identify the sounds produced by the animals.
The ideal method for identifying individual animal sounds typically involves a deep learning approach. However, a major drawback of this method is its reliance on extensive labeled data. In our research, we faced a significant challenge due to the limited availability of labeled sound samples. This constraint made it clear that utilizing a deep neural network would not be effective. To maximize the value of our limited data, we developed an alternative strategy using less complex models. Our approach involved dividing the continuous sound stream into several short segments, each slightly overlapping with the next to ensure no critical sounds were missed. The next step in our pipeline was to extract various features from each sound segment. These features were then input into a simple machine learning model for classification. This model was now trained to identify whether a particular sound segment contained any of the targeted animal sounds.
Despite incorporating several simpler machine learning classification models, we found their performance on unseen data to be suboptimal. We explored various avenues to enhance their effectiveness, but the root of the problem remained a lack of sufficient labeled data. The conclusion was clear: we needed more labeled data. To address this, our next step was to establish an online labeling interface using the open-source data labeling tool, Labelstudio. Simply labeling all available data would have been inefficient, especially since we already had some labeled data that could expedite the process. Therefore, we fine-tuned a machine learning classifier to pre-screen the audio files, identifying those most likely to contain the target animal sounds. This approach successfully filtered out about 50% of the sounds, thereby streamlining the data labeling process and enhancing its efficiency significantly.
Looking ahead, the ultimate goal remains: to achieve automated identification of specific animal sounds and monitor these via a web application. We maintain that a deep learning strategy is likely to yield the best results, which inevitably means that a substantial amount of labeled data is essential. With some additional labeled data, we could re-employ our current pipeline to assess its performance with this expanded dataset. This may already deliver satisfactory outcomes. However, if it falls short of our expectations, the next logical step would be to replace the simpler machine learning classifier with a more sophisticated deep neural network. This shift could provide the enhanced accuracy and efficiency we seek in our project.



